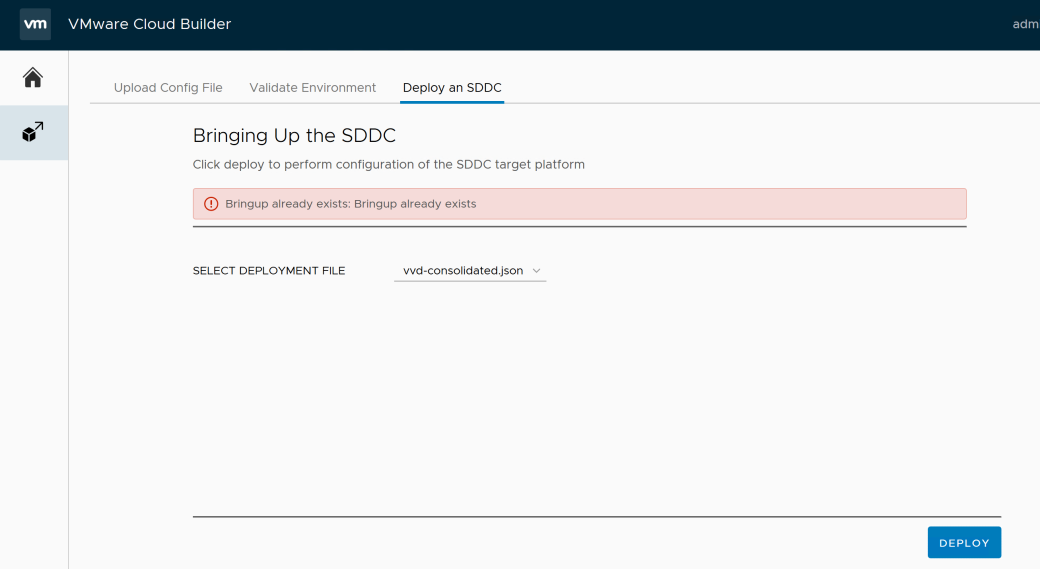
The latest VVD 5.0 version contains a tremendous tool called Cloud Builder. It can automate the full deployment of VVD all the way to vRealize Suite. It can do a consolidated or standard architecture, single site or dual site setup. If you are testing the tool, you might end up with the error “Bringup already exists” when trying to run Deploy.
Remove Stuck Requests in vRSLCM Through API
vRealize Lifecycle Manager is a brilliant tool for managing your vRealize environment. However, sometimes things go wrong during request runs, and the request stays looping forever. For instance, I’ve had this happen during vROps deployment where the install of vROps just gets stuck and never finishes, but vRSLCM keeps waiting for the task to finish. Unfortunately vRSLCM doesn’t have an option in the GUI to remove these stuck or looping requests. Luckily, there is an API that can do the task, but it’s not documented properly in the vRSLCM documentation.
vRA Health Tab Empty After Migration
For a while now, vRA has contained a Health Service that can be used to check and validate the vRA environment. It’s a great tool, and very necessary when migrating from an older vRA versions. In this case, it can be used to identify if any of the VMs and appliances in the environment use an older version of Gugent Agent. Upgrade of the Agent is a necessary step for a successful migration.
Sometimes the Health tab, which is used to access the Health Service, can be blank. There are many reason for this, but I encountered a specific one during migrations that was interesting. The vRA documentation has a tip that if the tab is empty, you need to stop the service and start the service again. Unfortunately this did not work for me.
Docker, Admiral, Harbor, VIC, VCH, Photon, CodeStream, Oh Boy…
Confused? I know I am. The container world is moving fast, and VMware is pushing new products left and right. Well, most of them have been around for some time, but not necessarily as finished products. The VMware container strategy is shaping up, so let’s dive into the deep end and see what is going on.

Migrate vRA VMs Between Clusters in EHC
Moving vRA VMs around can sometimes be tricky. vRA itself doesn’t provide much tools to do VM migrations, so some operations have to happen in the vSphere layer before they can be moved in vRA. Although vRA Data Collection functions marvellously, there are some changes that require a manual intervention in vRA to make sure things are in order. Simple resource changes are easy for vRA, but when you have to migrate a VM from one cluster to another, vRA won’t like that. vRA Reservations are mapped to underlying clusters, and changing clusters ultimately means changing Reservations.

Using vRA 7.3 Workload Placement with vROps 6.6
The latest vROps major version 6.6 introduced an interesting feature called Workload Balancing. The clusters in vSphere tend to get unbalanced as workloads mature, and this feature makes it possible to automate the movement of VMs between vSphere clusters and datastores using vROps metrics.
vRealize Automation 7.3 also has a new feature called Workload Placement, where it uses vROps to get metrics about the target environment and to make better decisions where to place a particular machine. Without vROps, vRA places the workloads to suitable reservations that can fulfil the machine request requirements. In case there are more than one options, vRA uses the priorities set in Reservations and datastores for placement. It doesn’t take the current CPU/memory load in to consideration. The new Workload Placement leverages the vROps feature mentioned earlier for more intelligent machine placement, but there are some major limitations. If you are using Storage Reservation Policies, things get tricky. Setting this up is relatively easy, but the documentation fails to mention everything. Let’s have a look at how the feature is configured and what the limitations are.
Imported VMs Disappear after vRA 7 In-Place Upgrade
Getting ready to upgrade vRA from 6.x to 7.x? If your system contains imported VMs, pay attention.

There’s a known issue with imported VMs when doing an in-place upgrade. VMware has a KB 2150515 on the issue, but you have to do the fix before you upgrade. As it happens, we noticed the KB after the upgrade was done and things were in a bad state. If you can, use the KB. If it is too late, read on.
EHC 4.1.2 Scalability and Maximums
EDIT: Updated for EHC 4.1.2
Architecting large scale cloud solutions using VMware products have several maximums and limits when it comes to scalability of the different components. People tend to look at only vSphere limits, but the cloud also has several other systems with different kind of limits to consider. In addition to vSphere, we have limits with NSX, vRO, vRA, vROps and the underlying storage. Even some of the management packs for vROps have limitations that can affect large scale clouds. Taking everything into consideration requires quite a lot of tech manual surfing to get all the limitations together. Let’s inspect a maxed out EHC 4.1.2 configuration and see where the limitations are.
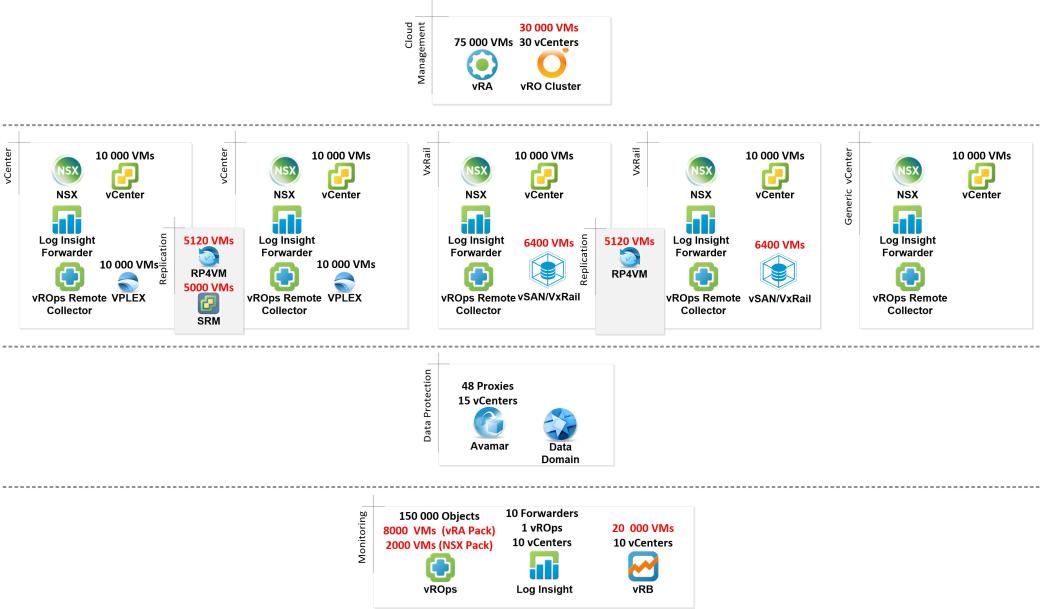
Latency Rules and Restrictions for EHC/vRA Multi-Site
EHC 4.1.1 can support up to 4 sites with 4 vCenters across those sites with full EHC capabilities. On top of that, we can connect to 6 more external vCenters without EHC capabilities (called vRA IaaS-Only endpoints). There are many things to consider when designing a multi-site solution, but one aspect is often omitted: latency. If you have two sites near each other, latency is usually not a problem. When it comes to multiple sites across continents, then we need to consider roundtrip times (RTT) between the main EHC Cloud Management Platform and remote sites very carefully. There are many components that connect over the WAN to the main instance of EHC and vice versa, and some of the components are sensitive to high latency. It’s also difficult to find exact information on what kind of latencies are tolerated. Often the manuals just state that “can be deployed in high latency environments” or something similar. Let’s try to find some common factors on how to design multi-site environments. For a quick glance of the latencies involved, scroll down to a summary table at the end of this post. For a bit more explanation, read on!
Configure Log Insight Forwarder in Enterprise Hybrid Cloud
As part of our Enterprise Hybrid Cloud, we deploy a Log Insight instance to gather the logs from the various components of the solution. Back in the days of EHC 3.5 and older, we used to have a single Log Insight appliance or a cluster, and all the syslog servers were pointed to that. Since EHC 4.0, that design has changed. Now we utilize a separate Log Insight Forwarder instance to collect and forward some of the logs. The reason behind this change is the ability of EHC 4.0 and newer to connect several remote sites (or vCenters) to one main instance of EHC. We want to collect logs from the remote sites as well, but it’s not efficient from networking perspective to collect the logs straight from the components over WAN to the main Log Insight cluster. Log Insight has a nifty built-in feature called Event Forwarding, that can push the local logs to a central location. It’s designed to work over WAN, so it can optimize the network usage and also can encrypt the traffic between sites. Pretty cool! There are plenty of other reasons to use forwarding as well.

